
Hey Folks, as you may already know about the various web crawler tools used to crawl the documents available on the web application and one of them is going to present called “waybackurls“, which works in the same way as other web crawlers. Basically the tool accept line-delimited domains on stdin, fetch known URLs from the Wayback Machine for *.domain and output them on stdout.
Let’s take a look 🙂 !!
Install Golang
To operate this tool, it is necessary to install the Go utility in your system, otherwise you cannot operate it. Let’s install it easily using the following command.
apt install golang
Waybackurls Tool Installation
Once the installation is done, we can download this tool through the Go utility and also operate it from anywhere.
go get github.com/tomnomnom/waybackurls
waybackurls -h
Done 🙂 !! Everything looks good and the time has come to test this tool. Only we need to leave a target URL in the command that we want to crawl and that’s it. It will automatically crawl all the URLs and documents of the web application with the help of sitemaps.
Usage 🙂 !! waybackurls < URL >
waybackurls testphp.vulnweb.com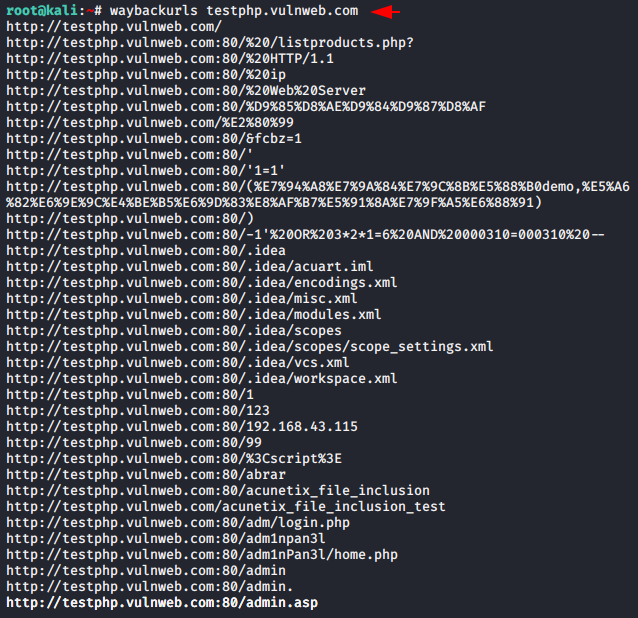
Exclude Subdoamin
By default it automatically fetches all subdomains of a given domain and starts spiders scan on them as well but if you only want to crawl specific given domains then you can mention “-no-subs” after gives the URL.
Usage 🙂 !! waybackurls < URL > -no-subs
waybackurls testphp.vulnweb.com -no-subs
Save Output
There is no specific command given in this tool to save the output but if you want to save your output in txt file then you can use the following command.
Usage 🙂 !! waybackurls < URL > > < output file name >
waybackurls fintaxico.in > res.txt





Whats up! I just wish to give a huge thumbs up for the good information you will have right here on this post. I will probably be coming back to your weblog for more soon.