Hey Folks, in this tutorial we will discuss the “web crawler” tool that will help to find important and hidden files or directories from web application. Let’s talk about the interacting and features of this tool. There is no such special feature in this tool but when we use it then it will look like both GUI and CLI 😁 . As we mentioned above it is a web crawler and web scraper tool written in Golang and may be useful for a wide range of purposes such as metadata and data extraction, data mining, reconnaissance and testing.
Lets take a example 🙂 !!
Installation
The tool is written in Golang language, so before installation we have to fulfill some dependencies of this tool and configure this one by executing the following command.
sudo apt install -y golang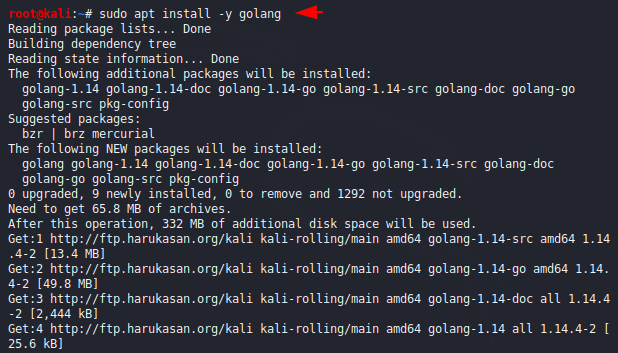
Now we install the tool from the github page and go the directory of the tool. After doing this we build the application through Go language and move it permanently after which we can easily run this tool by entering the name from anywhere.
git clone https://github.com/saeeddhqan/evine.git
cd evine
go build .
mv evine /usr/local/bin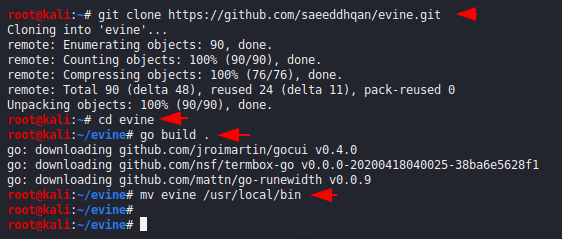
We can see the features of this tool by executing the “help” command.
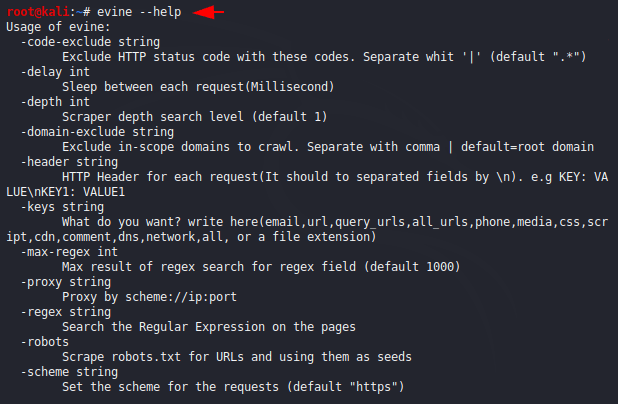
Usage
The installation was simple, but can be difficult for users to use as it has some different features which are given below.
- Enter – Run crawler (from URL view)
- Tab – Go to Next view
- Ctrl+Space – Run crawler
- Ctrl+S – Save response
- Ctrl+Z – Quit
- Ctrl+R – Restore to default values (from Options and Headers views)
- Ctrl+Q – Close response save view (from Save view)
Crawling
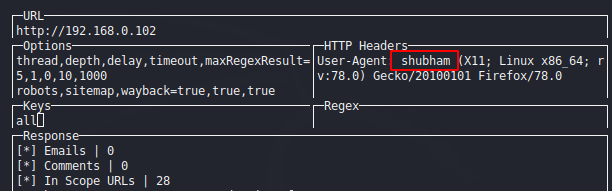
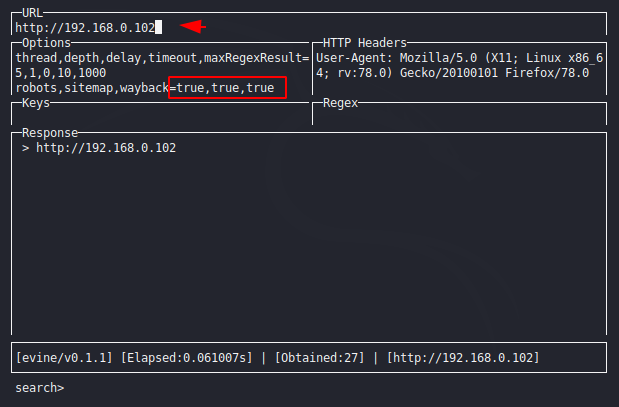
You must have to read the above instructions because it will help to control this tool. Now here we will give the URL and click on the tab button and go to the options section and true all the options that we want to crawl.
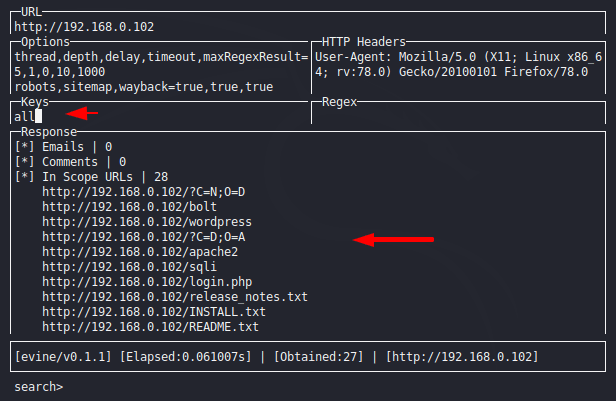
We will not see results before entering all on the key section and after entering “all” keywords we can see that result.
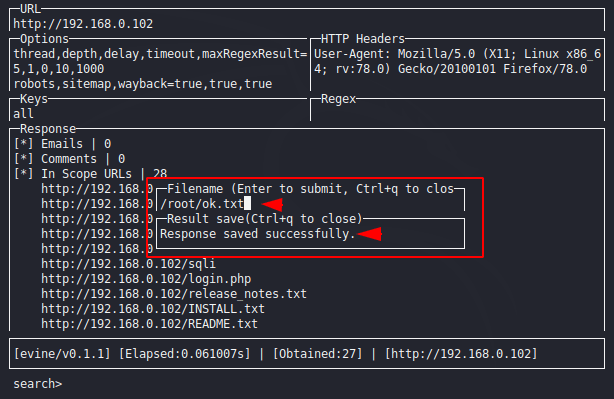
Save Output
If we want to save our output or results then we need to input “Ctrl+S” through the keyboard on response section, give the file name and exit it by “Ctrl+q“.
Filters
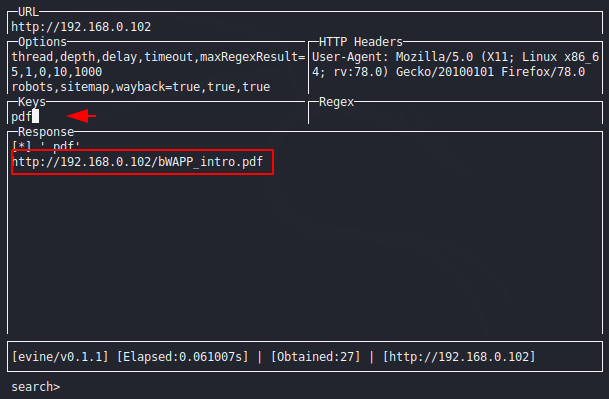
Key sections are used to get accurate results by adding fillers. For example you can see below that after adding the PDF keyword it shows only the results that match the given keyword.
Custom Header
Some websites do not allow us to do crawling, then we use separate-2 methods and this is one of the ways in which we send different information to the server through header manipulation.